

- Sat 22 December 2018
- Deep Learning, Convoluted Neural Network, Image Prediction
- William Miller
- #Deep Learning, #CNNs, #Image Prediction, #Space
As of the most recent estimates, there are more than 2 trillion galaxies in the universe. While telescopes are continually capturing images of these galaxies, the sheer number of them makes their classification by humans an unlikely, if not impossible, task. Fortunately, with the creation of neural networks that excel at image classification, this problem is imminently solvable. I set out to see just how accurately galaxies could be classified by a convolutional neural network, applying a pre-trained neural net to images from the Sloan Digital Sky Survey.
In 2007, the Sloan Digital Sky Survey published a data set consisting of over a million images of galaxies. These were eventually added to other data sets of galaxy images by a team of scientists known as Galaxy Zoo, which facilitated the crowd-sourced labelling of these galaxies. Much of this data was eventually released as a part of a Kaggle competition in 2013, which provided galaxy images along with the probability of classifications applying to each galaxy. The data resulting from this crowd sourcing can be found here.
Getting to know the data
One of the initial challenges in obtaining actual galaxy classifications from this data is that the features are determined by answers to questions in a designated task list (pictured below). Each feature in the data set represents a percentage of crowd-sourced data labels that assigned a classification to an image. For instance, if 62% of labellers gave an answer of "No" on task 3, a value of 0.62 would be assigned Class 3.2.
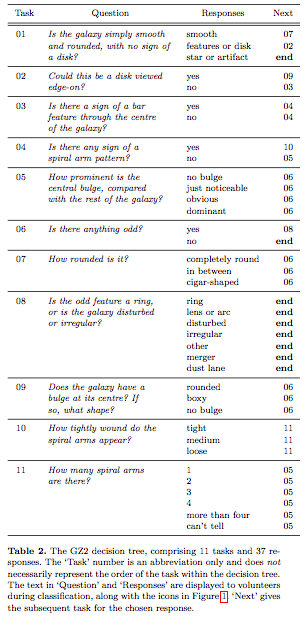
The above chart can, to at least some degree, be distilled into Hubble's galaxy classification system. As can be seen below, this divides galaxies into ellipticals, spirals, and spiral bar classes.
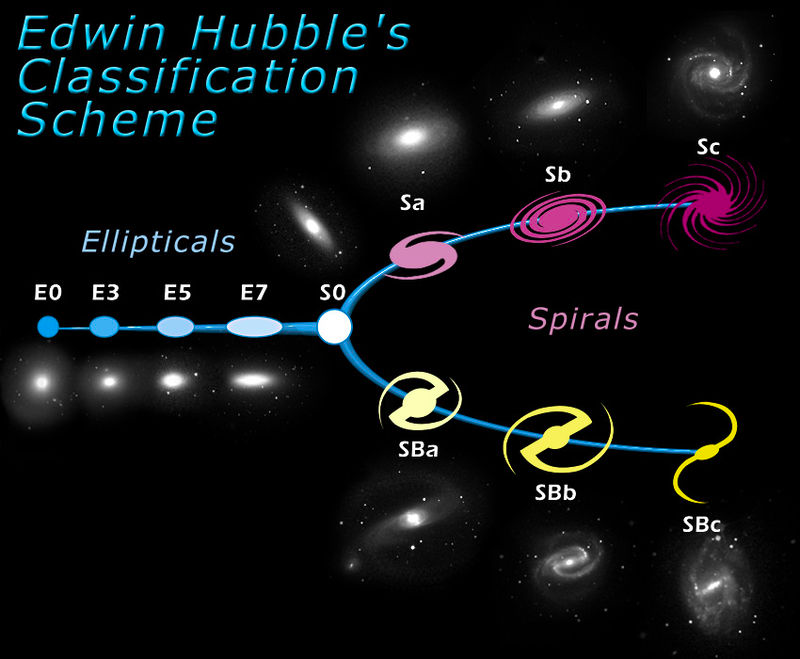
In the crowd sourced data, ellipticals would be indicated by class 1.1 in the data. Spirals would be indicated by classes 4.1 and 3.2 together. Spiral bar galaxies would be indicated by classes 4.1 and 3.1 together.
Subclasses of each of these would be indicated in classes 7 (degrees of elliptical), or 10 and 11 (types of spiral and spiral bar galaxies).
Before immediately training a model to predict to the crowd-sourced data labels, it is worth exploring the shape of that data a bit and verifying its integrity. As a first step, I wanted to ensure that there was actually a high degree of agreement among labellers - if the maximum certainty for most of the classes is no higher than 60%, the data may be mostly useless.
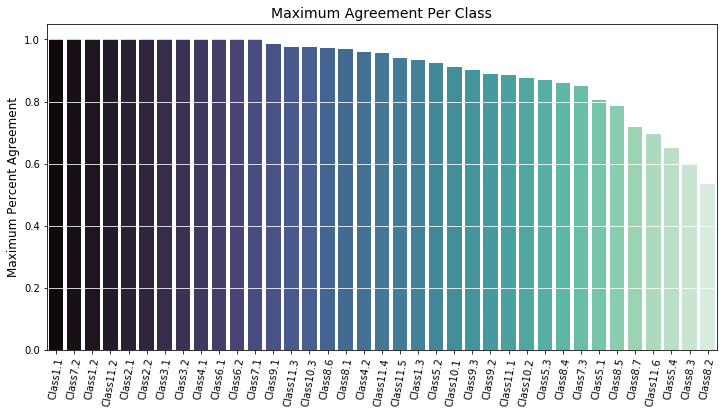
Fortunately, as can be seen in the image above, most classes have a maximum agreement of at least 80%, indicating that there are at least some galaxies which had a classification that was generally agreed upon.
Next, it would be good to know how much agreement there is for each class.
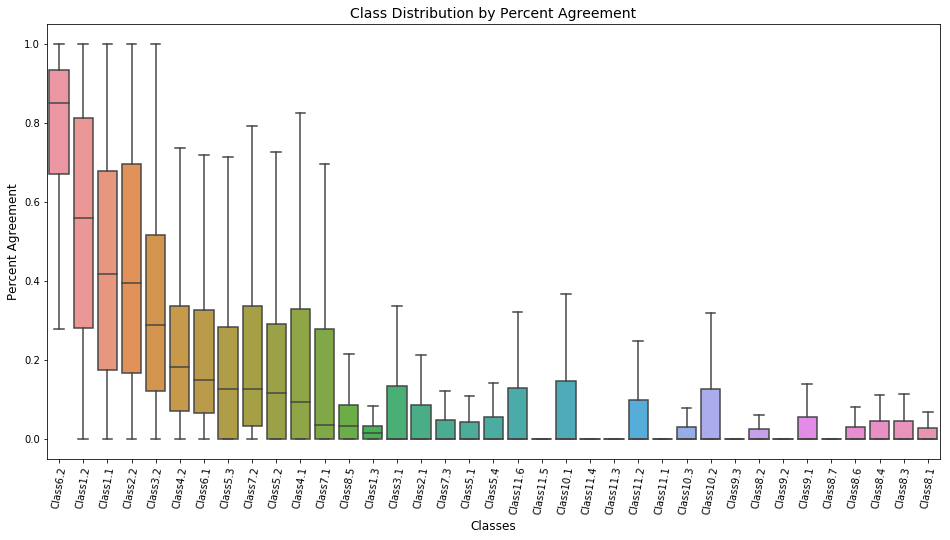
Important information that can be gleaned from these graphs, from left to right:
- There is nothing "odd" about the majority of labelled galaxy images. (Class 6.2 compared to 6.1)
- More than half of galaxy images include some kind of feature or disk, but a significant range is observed in every quartile (Class 1.2)
- Around 40% of galaxies could not be disks viewed edge-on, though significant range is observed in every quartile. (Class 2.2 compared to 2.1)
- Where galaxies are not disks viewed edge-on, most tend not have have a bar (Class 3.2 compared to 3.1)
I also found it useful to ensure that galaxies which had a high degree of classification agreement appeared as I thought they would. The images below were found by taking the first example that met each of the following criteria:
- Ellipticals: 90% of labellers assign class 1.1
- Spirals: 90% of labellers assign both class 4.1 and 3.2
- Spiral bars: 90% of labellers assign both class 4.1 and 3.1
Repeating the exact same criteria, except with a threshold of 60%, yields encouragingly similar results, even if the images are somewhat less distinct.


Building a convolutional neural network - Prerequisites
Getting started with an Amazon EC2 Server
When I first attempted to train a CNN to predict galaxy class labels from images, I quickly realized that my laptop was not going up to the task. Even if I happened to set all of the parameters optimally on the first try, it would have taken roughly 2 days to train for only 10 epochs. I realized that I needed to learn how to harness some external processing power. After doing some research on my options, I turned to Amazon Web Services. This turned out to be a bit of a process, so I will briefly outline the steps I went through below.
Initial set up
I started off by following the steps laid out in this very helpful guide. There was one major hitch, however. AWS would not let me select a p2.xlarge instance, which after thoroughly looking into it, was the option I decided I needed. It turned out that my default limit for this type of instance was automatically set at zero, and I had to convince them - over the course of 2 weeks of communication (mostly on my part) - that this was a thing I actually needed for my project. Fortunately, they eventually granted a limit increase to run one p2.xlarge instance. I then completed the guide I linked to above.
Migrating the project
So I finally had the instance up and running, which after all the negotiation, felt like more of an accomplishment than it should have. However, I ran into a roadblock, as I had never needed to migrate data to or from a remote server anymore. After doing a bit of research, I discovered the I should be using the scp command and the syntax of it.
The bit of magic that did the job was:
scp -i AWSKeyFilename.pem -r ubuntu@(instanceaddress):~/remotepath localpath/
where "instance address" was the text copied in step 6 of the guide I linked to above, and the rest is hopefully obvious. I included the '~/' before "remotepath" and "/" after "localpath" above because these turned out to be important to include in the paths. Thus began the long process of copying tens of thousands of images of galaxies onto my EC2 server.
Selecting an environment
When I attempted to train the model on my laptop, I had decided to use Keras with a Tensorflow backend, and I opted to stick with this choice. Before starting my project on the remote server, it was important to activate this environment (using Python 3.6) by typing "source activate tensorflow_p36". I was then ready to start up my jupyter notebook and start refining my project.
Image processing
Having looked through a large number of the galaxy images, I had discovered that they were all centered on the galaxies to be classified and that there was a large amount of irrelevant space around each galaxy. I found that I could crop the images to half the size around the center of each, which would decrease the number of irrelevant artifacts in each image and exponentially decrease training time. I accomplished this with the function below, which I included in my batch generation pipeline.
from skimage.transform import resize
def center_crop_images(filepath_list, image_shape_tuple):
"""
Description:
Import images contained in filepath_list, read, transform according to image_shape_tuple
Inputs:
filepath_list = List of filepaths containing images to process
image_shape_tuple = Tuple in the form of (channels, height, width)
scale_factor = The factor by which the resolution of the images should be multiplied
"""
width, height, channels = image_shape_tuple
# Get count of files in to crop, as this will be the first element in the output array
path_count = len(filepath_list)
# Divide width and height by 2 in order to allow cropping around center
x_scale_unit = int(height/2)
y_scale_unit = int(width/2)
# Create an empty array in the shape of the final output
img_array = np.zeros(shape=(path_count, width, height, channels))
for idx, path in enumerate(filepath_list):
# Read image
img = plt.imread(path)
# Crop image
img = img[x_scale_unit:x_scale_unit*3,
y_scale_unit:y_scale_unit*3, :]
# Resize image to properly fit cropped dimensions
img = resize(img, (width, height, channels)) # can be used for resolution downscaling if needed
# Add image to the output array
img_array[idx] = img
return img_array
 |
 |
Building the Convolutional Neural Network
Now for the more exciting stuff. After doing some research on various CNNs pre-trained for image prediction, I opted to modify a VGG16 architecture with imagenet weights for my neural network. However, I discovered that I did not have the clearest idea of how to link my training targets to data from the images in batches so that the neural net could be trained on it. I then learned how to create a custom batch generation class - the code for which is below.
class Batchifier:
"""
Class for creating training, testing, and validation batches.
"""
def __init__(self, parent_path):
# Describe directory structure
self.path = parent_path
self.target_path = 'target_data/'
self.training_path = parent_path + "train_images/"
self.testing_path = parent_path + "test_images/"
self.validation_path = parent_path + "validation_images/"
def get_filepaths(directory):
# Converts directory structures to lists of filepaths
return [f for f in os.listdir(directory) if f[-4:] == '.jpg']
# Convert each directory to a list of filepaths
self.training_img_files = get_filepaths(self.training_path)
self.testing_img_files = get_filepaths(self.testing_path)
self.validation_img_files = get_filepaths(self.validation_path)
def get_targets(self, target_path):
"""
Description: Separates target data from key values and returns a dictionary of target data.
Inputs: Target data in a csv file.
Outputs: A dictionary of target values with labels as keys and target data as values.
"""
# Create dataframe from the name of the csv file in target_path
targets_df = pd.read_csv(target_path + 'targets.csv')
# Create empty dictionary for temporary storage of target data
targets = {}
# Iterate through the targets_df dataframe
for idx, row in targets_df.iterrows():
# Create a mask to select only the label data
key_mask = row.index.isin(['GalaxyID'])
# Convert the label data to a string to use as a dictionary key
key = str(int(row['GalaxyID']))
# Use the inverse of the key mask to select only the target data
target_values = row[~key_mask]
# Use the key to store the target values in a particular instance of the targets dictionary
targets[key] = list(target_values.values)
return targets
# Use the get_targets function to assign target data dictionary to self.targets
self.targets = get_targets(self, target_path)
# Create an ID from the filename of each image
def get_galaxyid(self,fname):
return fname.replace(".jpg","").replace("data","")
# Get the target data assigned to any particular label.
def find_label(self, label):
return self.targets[label]
batch_object = Batchifier(data_path)
This was then referenced by the generator for each of the training, validation, and test sets as follows (substituting the filepaths and appropriate variable names for each set, of course):
def TrainingBatchGenerator(batch):
while 1:
for f in batch.training_img_files:
# Crop image contained in "f".
X_train = center_crop_images([batch.training_path + '/' + fname for fname in [f]], (212, 212, 3))
# Get the ID (label) for this image file
galaxyid_ = batch.get_galaxyid(f)
# Get the target data associated with this ID
y_train = np.array(batch.find_label(galaxyid_))
# Ensure the target data is shaped appropriately to the number of classes
y_train = np.reshape(y_train,(1,37))
# Return formatted training and target data.
yield (X_train, y_train)
Having created a way to feed data to my neural net, I finalized my network. All of the lines prior to "flatten" are part of the VGG16 architecture. To better enable the network to better fit my data, I flattened the output from this architecture, and I added a 1024 neuron dense layer, a dropout layer, another 1024 neuron dense layer, and a final dense layer to set the network output equal to the number of classes. Choosing "sigmoid" activation over "softmax" in the final layer was very important in this case, as "softmax" forces all classes to sum up to one, which is not the case with the classes in the target data. The purpose of the dropout layer was to regularize the network, dropping out random neurons during training to prevent the model from overfitting to the training data.
The code to accomplish this was relatively simple, and was written as follows:
# Initialize a VGG model using pretrain imagenet weights, not including the top-most layers
vgg = VGG16(weights='imagenet', input_shape = (212,212,3), include_top=False)
#Adding custom top layers to allow training for this particular data
x = vgg.output
x = Flatten()(x)
x = Dense(1024, activation="relu")(x)
x = Dropout(0.5)(x)
x = Dense(1024, activation="relu")(x)
# It is important to use "sigmoid" activation in this case, as probabilities for each class do not add to 1.
predictions = Dense(37, activation="sigmoid")(x)
model_final = Model(inputs = vgg.input, outputs = predictions)
The final architecture of the network is summarized as:
_____________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 212, 212, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 212, 212, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 212, 212, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 106, 106, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 106, 106, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 106, 106, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 53, 53, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 53, 53, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 53, 53, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 53, 53, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 26, 26, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 26, 26, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 26, 26, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 26, 26, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 13, 13, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 13, 13, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 13, 13, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 13, 13, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 6, 6, 512) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 18432) 0
_________________________________________________________________
dense_1 (Dense) (None, 1024) 18875392
_________________________________________________________________
dropout_1 (Dropout) (None, 1024) 0
_________________________________________________________________
dense_2 (Dense) (None, 1024) 1049600
_________________________________________________________________
dense_3 (Dense) (None, 37) 37925
=================================================================
Total params: 34,677,605
Trainable params: 34,677,605
Non-trainable params: 0
_________________________________________________________________
This model was compiled with the "Adam" optimizer, with the learning rate set to $1*10^{-5}$ and the rest of the parameters set to the defaults. I then trained the model for 50 epochs with callbacks for early stopping, checkpoints, and tensorboard. This trained relatively quickly on the AWS image, with a training time well under 3 minutes per epoch. The lowest mean squared error of the model against the validation data was 0.0084 after training for 40 epochs. Evaluating this model against the data I held out for testing gave an MSE of 0.0094. A plot of the training history is below.
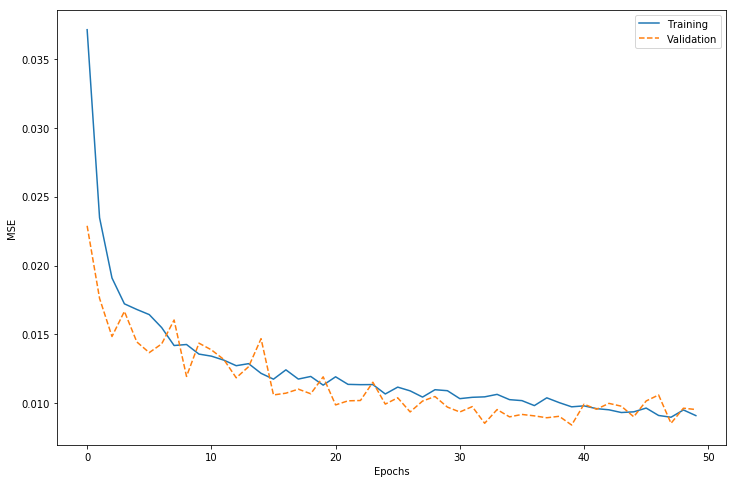
Evaluating the convolutional neural network
Having trained the convolutional neural network (CNN) to a low MSE and evaluated the performance of the network on the testing data, I could now use the testing images to dig a little bit further into how the model predictions compare with the actual data. I repeated much of the same process that I used in exploring that data initially on the predictions generated by the CNN.
One thing which stood out as interesting is that the maximum agreement per class tended to be much lower in the predictions than it was in the actual data, as can be seen in the image below.
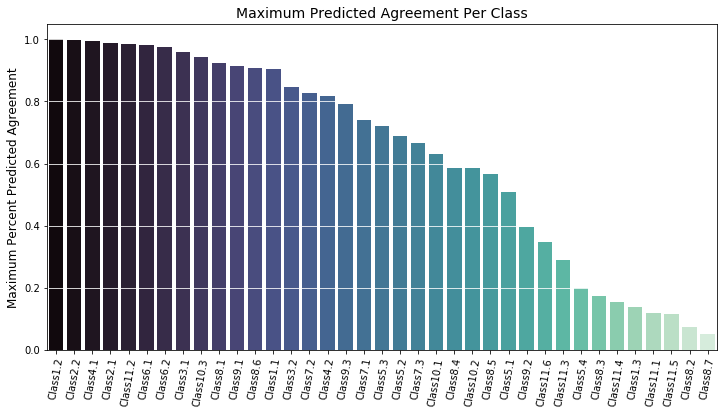
This ended up being due to the fact that classes which had higher average percentages of agreement among data labellers (as seen in the "Class Distribution by Percent Agreement" plot above) tended to have higher mean squared errors than those which had lower percentages of agreement, as can be seen in the following bar chart.
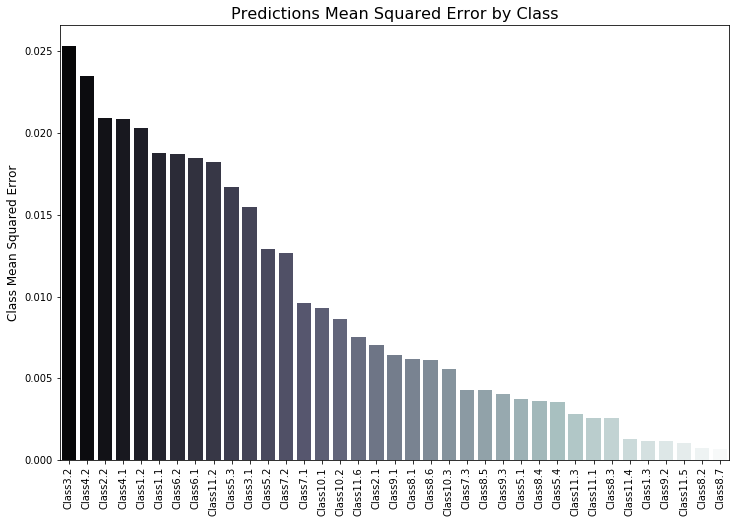
For me, knowing about the performance of the neural network is one thing, but what is really interesting is seeing it actually make useful predictions. To see this, I had it make predictions on some images it had not yet seen and took the first samples it returned with high degrees of agreement for the three basic Hubble classes as seen above. The images that follows are from predictions the neural network made on images it had been exposed to in training or validation:


It looks like the neural network is a success! Each image clearly corresponds with its Hubble classification, demonstrating that it has successfully learned to classify galaxies.